This page is my "blog".
It's just a place to leave some thoughts and things that are going on. Some will be about software, some about humans and some about both. I'll try not to post about the brand of my new toothbrush unless it's really important :-)
22 Oct 2017
Fairphone is making more steps to its goal of modular phones which are used longer (instead of, for instance, buying a new phone because the camera is a bit outdated). I have a (almost) two-year old Fairphone2, and making photos and videos is one of its most important functions. Thus, I bought the new camera module.
The new module upgrades from 8 to 12 megapixels, but there is much more to a camera than the pixel count.
Here I'll show a few before and after pictures for any Fairphone 2 owners who are interested. I'll show original first, then the new camera.
First picture: Objects in fall afternoon sunlight, no special instructions


The original camera did make some odd choices when making the picture, especially with lightning. The new module got it much better. This is also a reminder that a camera is hardware, but it needs software making good decisions.
Second picture: Objects in fall afternoon sunlight, focus on the sunflower


When I focused on the sunflower, the original camera made a better picture. The new camera, however, gets more out of the scene. The table isn't as dark, and the colours are generally more natural.
Third picture: Freezer magnets on slightly reflective surface


It's less obvious, but I think the new camera gets details like natural colours and reflections noticably better.
I also made a comparison picture in a quite dark setting, and both cameras made really different choices. The old one caught too much light, the new one slightly too little. I installed OpenCam to see what difference another camera app made, and that result was much better.
I recommend getting the new camera if photos are important to you (e.g. you make 90% of the family pictures with your Fairphone2 and you believe 45 EUR are worth catching scenes slightly more naturally) and also to not underestimate what a different app could do, as well.
10 May 2017
In which I show my solution for listening to audio and watching videos at home in the digital way, with an acceptable quality (for most people), but for a very little costs and almost no hassle getting it to work.
Here's the short rundown on requirements I had and maybe you also agree on (which in turn means you might want to read on):
- All digital (sound and video files & streaming services)
- hassle-free setup - this is for the bulk of people who like me, are not in for weeks of research or tooling
- very low costs
- no vendor lock-in & use of standards where possible
- acceptable (not necessarily the world's greatest) audio quality
- remote control for everything (by mobile phone or actual remote controls)
And here is what what I actually use:

PlayOn Harddisk Media player 40 EUR
Google Chromecast 39 EUR
Raspberry PI as music box ~70 EUR
Envaya Bluetooth Audio Player 140 EUR
--------------------------------------------------------------------------
289 EUR
Why? - So here's the problem
Listening to music and watching videos at home. Everyone (in a modern household) wants to do this, of course. These days, however, the number of choices how to do it is vast, to the extent that researching what to buy can take forever. You can also built and configure a lot of things yourself, for instance using a raspberry pi and a custom-made luxurious soundcard. I understand that there were tough choices to make 30 years ago, as well, like how large the TV should be and if gold cables are really needed to get everything out of your audio signal.
I believe that today the number of sources for media has increased (and I'm only counting the digital cases for me anymore, really), because next to playing sound and video files from your hard drive there are now a number of relevant streaming services you might want to use.
On the hardware side, a lot of devices are on the market now, which all do something to play audio to you, in varying locations and quality. In fact, it's a young market with a lot of companies trying to develop exactly what we need. It's exhausting to do research there!
A lot of these new solutions are designed to lock you in and to upsell, something Apple is really good at. They want you to buy something wireless for every room in your house and also for on-the-go and what started at 200 EUR ends up at 1300 EUR and you need to keep using this system from now on.
The (my) solution
So I decided to lower my expectations with respect to audio experience, otherwise I would never install something modern. Otherwise, I believe I got pretty close to my requirements. Let's list what I bought:
Harddisk Media player
This little device plays almost any movie file you give it and it comes with a remote control (not pictured). I like USB sticks, which I can place there, but you could also connect a computer network cable and read files from some place in your LAN. I bought this a few years ago for around 90 EUR I believe (it's out of stock now), but nowadays the devices all seem to cost around 40 EUR. Connect to your TV via HDMI and it works.
Chromecast
Google makes this nifty little device which connects to your Wifi and then lets you show most of the content your phone screen would show, but streamed fromt he Wifi via the Chromecast to a connected screen, i.e. your TV. Your phone becomes a remote control. For streaming a few things which are well-supported (Youtube almost all of the time to be honest), this works really well. You have to help ot find your Wifi but that is very nicely done. Its usability breaks down though if you are streaming content via an app that is not supporting it or if you do not want the whole Google app stack on your phone (like I'm trying to these days), so I'm eagerly awaiting more innovation in this gadget area.
Envaya Bluetooth Audio Player
The audio speaker is the area where one can lose the most time and money. I settled for a bluetooth speaker I can put anywhere I want, has decent reviews about its sound (not great, but reviews from people with better ears than me -audiophiles- are tiring), good bass, an AUX in and can even charge your phone. You could pay less money here, but it is something you'll use a lot. Using the AUX in, it can even give your TV watching experience a boost. This works out of the box.
Raspberry PI as music box
Streaming music to the speaker from the phone or laptop has its limits. It really occupies your phone for example, and if you want to play files from a hard drive you cannot reach that from your phone. So one might want to use a music server, which can be controlled from laptop and phone. Enter Pi Musicbox, a ready-to-use open source software package which can run a RaspberryPi for this purpose. Basically, it runs Mopidy, an open source music server oftwear, but neatly wraps it for perfect fit on RaspberryPi. The nice thing about Mopidy is that there a many mobile apps written for it, so you can control the Pi Musicbox nicely from a mobile device. Pi Musicbox plays files but also streams web radio stations and gives access to streaming services (though I cannot vouch for the Spotify support yet, still trying to get the most out of it - however, I still can use my phone here). By the way, the 70 EUR I listed above roughly cover the Raspberry PI (about 40 EUR) plus necessary extra things like an SD card, a case, power supply and a 32GB USB stick.
This gadget is the only one requiring a little work, but not much, as you can see:
1. put the Pi Musicbox image on a SD card
2. edit the config file so it finds your Wifi when it boots
3. put in the USB with your music
4. boot
14 Jun 2016
I dragged it with me after my contract ended in 2014, but I actually made a finished product out of my dissertation after all and defended it at the TU Delft this past May.

It was a pretty formal procedure as you can see, but quite a meaningful end to , and actually a fun day in the end.
The dissertation itself is available here officially, but also hosted by me. I'll post the propositions here:
1. Both the need for low computational complexity of bidding and for effective capabilities of planning-ahead can be addressed in a market mechanism for electricity, that combines the trade of binding commitments as well as reserve capacity into one bid [this thesis, chapter 3].
2. In settings where a uniform price changes dynamically over time and where these dynamics are influenced significantly by consumer behaviour, the ability of a consumer to comprehend price patterns increases if a large part of the other consumers reacts to price dynamics in a manner similar to how he himself reacts to them [this thesis, chapter 4].
3. Dynamic pricing for electricity can effectively reduce consumption peaks, also under the two conditions that the retailer promises an upper limit on prices and designs his pricing strategy for profit maximisation [this thesis, chapter 5].
4. A heuristic control strategy for a battery which is limited in capacity can be designed such that it has the following three advantages: it reacts fast, it can reduce overheating of a connected low-voltage cable significantly and (if prices are dynamic) it can partly earn back the acquisition cost of the battery by performing revenue management [this thesis, chapter 6].
5. There is not one silver bullet to the problem of how to manage a smart grid in the most efficient way. Each setting has its own requirements, given by its own set of stakeholders and design objectives.
6. To have a healthy and happy toddler is not to a small degree a matter of luck.
7. For the foreseeable future, concerns about privacy need to focus on computers and mobile phones, which directly expose political views and social contacts of their owner, rather than smart meters, which expose less meaningful data.
8. If users do not comprehend the reason why a novel technology interacts with them in the way it does, it will not be adopted, even if it is useful and resource-friendly.
9. Electricity grids are the largest man-made synchronous machines, and economies are the most complex man-made systems. To combine them leads to much more complexity than is commonly assumed, and the resulting systems will therefore never be completely understood.
10. In a referral network, where agents base their opinion about the performance of a service on those of other agents, it is beneficial for users if the agents forget old information at a comparable rate. [N. Höning: "Discounting Experience in Referral Networks", Master thesis, Vrije Universiteit (2009)]

I also was asked to write a very short summary, which might be useful here:
New developments require us to reconsider how electricity is distributed and paid for. Some important reasons are renewable energy, electric vehicles, liberated energy markets and the increasing number of smart devices. How we deal with these dynamics will affect important aspects of the upcoming decades, for example transportation, home automation, heating/cooling & climate change.
In order to keep the security of supply high and price fluctuations within acceptable ranges, we need to continuously make the decisions who will supply or consume electricity, at what price and at what time. The resulting complexity should not grow too high for small participants, otherwise novel technology might not be adopted. This dissertation contributes market mechanisms and dynamic pricing strategies which can deal with this challenge and reach acceptable outcomes in four relevant problem settings (mostly situated in lower levels of the electricity grid).
The most critical problem to address are intervals with very high power flow, or with high differences between demand and supply which need to be evened out. Such “peaks” can result in steep price movements and even infrastructure problems. We study decision problems that will arise in expected scenarios where peaks reduction becomes important. In order to arrive at an efficient and usable system, this research specifically looks into
Encouraging short-term adaptations as well as enabling planning ahead (of generation and consumption) within the same mechanism.
Ensuring that small and/or non-sophisticated participants can still take part in mechanisms.
Letting smart storage devices contribute to network protection.
We develop agent-based models to represent expected settings and propose novel solutions. We evaluate the solutions using stochastic computational simulations in parameterised scenarios.
A similarly high-level overview was given by me in a short presentation before the defense.
08 Dec 2014
Last week I attended DockerCon Europe 2014 which luckily happened in Amsterdam this year. I got my finger on the pulse of important developments in the ongoing evolution of the internet and a just-healthy dose of tech-optimism from current Silicon Valley prodigies. I thought I'd share my five favourite slides with a little comment on each.

The internet is still a technological Wild West. So many talented people. So much change and progress in technology each year. So many things you need to know to deliver something that doesn't break for some reason. So much still to achieve. Docker provides a usable (fast and well-documented) way to bundle into a container some things that you know are working, then upload this container on any server and expect this functionality to be up and running and simply work as you expect. It wasn't a DockerCon talk, but I like this short breakdown of what holds us back and why containers can help a lot (9 slides). At Softwear, we are using Docker both in the CI workflow and partly in production (by the way, let me know if you want to do influential UX or QA engineering work for us). The slide above shows the way of thinking going forward - build stacks from things you know will work and will also work together. Like Lego. Then make these light-weight stacks (your actual web applications) work together in creative ways. The current term for a picture like this is "Microservices". This slide from Adrian Cockcroft (who spent six years at Netflix) makes the point how useful Docker will be in more detail. Adrians presentation (all slides) probably generated the most food for thought. My favourite line (slide 26) is:
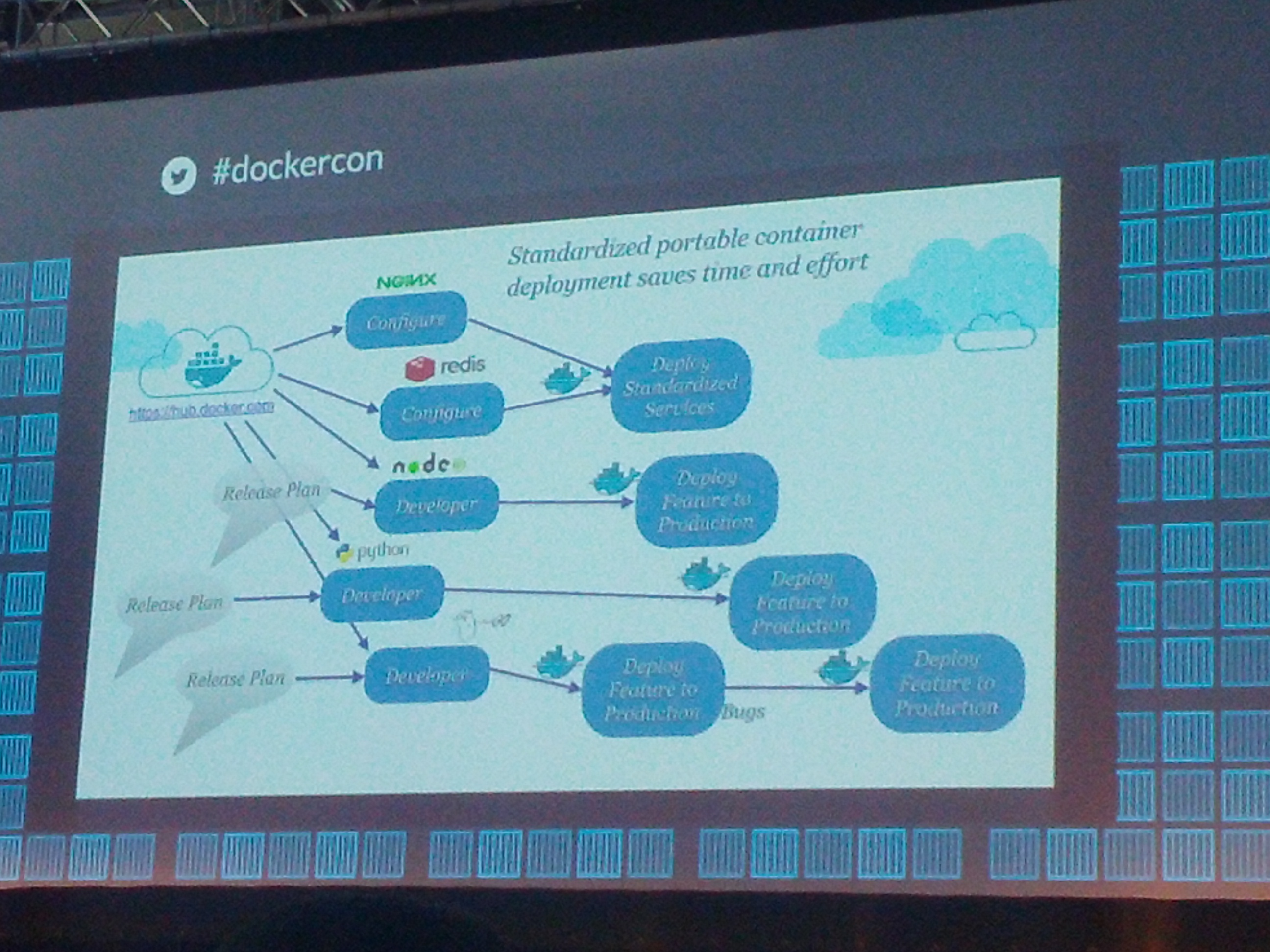{kind=link}
DevOps is a Re-Org!
meaning that software developers are taking over system operator/admin - tasks in any company which does not actually run data centers (which is becoming a very concentrated business nowadays).

Next, we get to some Silicon Valley - style notion of how suspected technology breakthroughs will change society. Docker Inc. CEO is asking here:
What happens when you separate the art of creation from concerns about production & distribution?
Subtly, there is a picture of the printing press. He wants to say that creators of web applications soon might need to worry less about how they will deploy their app such that it will work, as the "container revolution" will make this trivial. Of course, the web 1.0 kind of already did that for content. However, I can see how lowering a crucial technological barrier for inventing useful web applications can really be significant to innovation. We have a lot of content and ways to get it out there, now let us see what cool applications can be built to assist people everywhere in the world. And although we at this conference were a bunch of rich white males, poor people are hopefully getting access to cheap smart phones soon (Africa is a good example). I, too, find these times exciting. But I was glad to return to my normal life, and to cool down a bit.

This slide gives an indication of the scale of change we are seeing in the software world. Henk Kolk from ING told us how this large bank sees itself as a technology company now and removed everyone from their large IT team who can not program at least something. Being a programmer means being in demand right now but as his slide says as well, speed is key from now on. If you don't get on board with this new way of having tight control over your stacks, together with being totally flexible towards switching technologies, all you will be doing is to jump from one sinking ship to the next. I got both excited and chilled, actually.

An interesting take away of the current weeks is how Open Source currently works. Big money has gotten in on it, because in the software world, you have to invest in widespread and sustainable technology while also having a modern stack. This only works when an open source community carries the technology. Even Microsoft is coming around in major ways. Companies are actually employing the best open source programmers directly to stay on top of things. The industry is a bit different than other industries in this regard (hopefully actually leading the way). On the slide above, Docker Inc. CTO Solomon Hykes is giving us his current set of the rules that he thinks make a technology successful these days. As a consequence, Docker got some interesting new functionality (announced on the first conference day), but it was kept out of the core code - "Batteries included, but replacable".

But it is also not all agreement and happy collaborative coding. No, sir. The latest trend is that a company or a startup guides an open source technology. This makes progress faster and stable, but it can easily break if you annoy the comunity. Node was just forked, AngularJS is having a community crisis. The Docker community is also weary of the Docker startup Docker Inc. In fact, Solomon Hykes spent a lot of his time on stage at DockerCon Europe 2014 to discuss how he wants to succeed as a steward of the Docker technology, using a process he calls "Open Design" (see all slides here). There is an Open Design API through which all feature requests have to go, thus separating people acting on behalf of Docker Inc. from people acting on behalf of the Docker Open Source project - no matter which company pays them at the moment. They are creating and updating their own constitution which deals with this construct as we speak (of course in structured text files, so if you suggest a change, you submit a pull request). So the message of this slide above is simple and compelling:
The real value of Docker is not technology. It's getting people to agree on something.
Replacing "Docker" with any standard, this is something you could also have said during any time of rapid development and change. Interesting times.
P.S. There were some really smart people at this conference, building amazing companies and systems. We can expect to see a lot, e.g. from the Apache Mesos project. I could have chosen more technical slides for this list, but it would have taken me longer to explain why I fancy them. A lot of them were also quite intimidating, actually.
27 Mar 2014
I'm quite happy with how the visits to this website of mine have developed over the last year. Here are the monthly numbers:
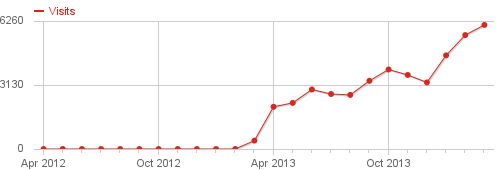
Btw, since March 2013 I use Piwik for my visitor analytics and am very happy. You should also be happy about that, because I don't store your metadata on Google's servers, only on mine.
An average week looks like this:
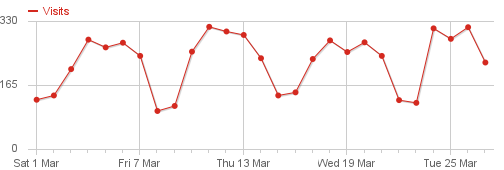
You can tell that people mainly come to my site on workdays, weekends are rather quiet. Why is that?
Well, in 2007 or so, I wanted to have javascript tooltips, or "popups" to display context to links when you hover them. I wanted to style them like I wanted. So I wrote a small script. It is very simple but the page explaining it creates almost all trafic to this website. Look at this example of page view numbers ("page views" are the amount of loaded web pages, where "visits" consist of one IP address performing one or more page views in one session) from (I think) one week:
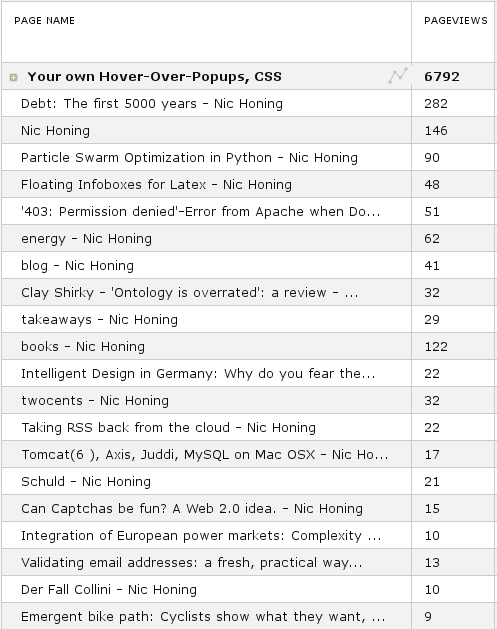
The trend is clear. Around 300 people come to that page about the little javascript thingy every day, and not much else I write gets attention. And as you can tell from the long list of comments there, many people use this javascript thingy in the websites they build. I actually get some satisfaction in making them happy, so I answer many of their questions and actually improve the codebase once in a while.
But here is the problem: There are many other similar scripts for this out there, and I never get mentioned when experts list libraries for such a feature (I have been mentioned in two or three forums, I think). Why do people keep finding this? I think the dirty little secret is that I called it a "popup", while the technically more correct term is "tooltip". Look at search queries that people used when they came to this page:
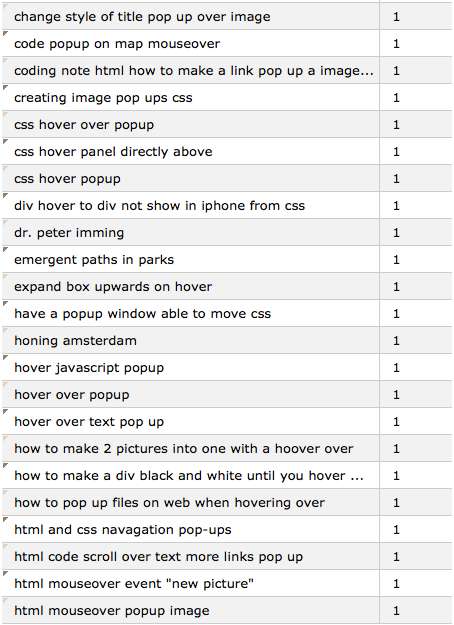
There you go. Me and a significant amount of people use the slightly wrong term, and that's what drives traffic here. Accidental linguistic match-making in cyperspace. Positive things come from this. The traffic probably improves my Google ranking a lot. Our interactions help my users get something done and make me feel some fulfilment. It's a weird world.
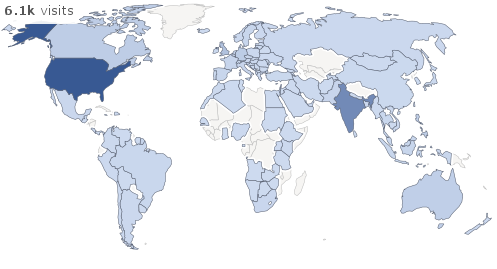
Speaking of the world, here is where my visitors are from Mostly english-speaking countries where a lot of web development happens:
You are seeing a selection of all entries on this page. See all there are.